Fixing Context Collapse in Long-Running Agents
Your agent gets worse the longer you use it. The problem isn't the model.
Your agent gets worse the longer you use it.
In long-running sessions, there is a point where your agent starts drifting. It forgets a constraint you set ten minutes ago. It calls the same tool again, with the same inputs. A decision from step three gets contradicted at step seven. Token costs climb while answer quality drops.
This is context collapse. It is especially common in long-running sessions on Telegram or Discord, where conversations keep going instead of restarting cleanly.
The context window has a hard limit, but degradation starts long before it is reached. Tool outputs pile up with no distinction between current and stale. Old constraints sit alongside new work, with no signal for which ones still apply. By the time you notice, the agent has already spent several turns working with the wrong context: giving worse answers, repeating work, and burning tokens on the wrong things.
Context collapse is a well-known problem, and the usual fixes only address parts of it. RAG can bring in external knowledge, but it does not manage the live working context of a running session. Memory systems can carry information across sessions, but they do not decide what should stay active in the current one. Summarization keeps the session moving, but it compresses away details the agent may need later.
These approaches solve real problems. They do not solve context collapse.
The problem is not just remembering old information. The problem is managing the right context inside the current session as the session grows.
What Contexto Is
Contexto is the in-session context management layer for long-running agents. It sits between the agent runtime and the model provider. At each step, it decides what stays active in the context window, what gets moved out, and what gets brought back when needed. As the session grows, Contexto keeps the agent focused on the current step without losing access to prior work.
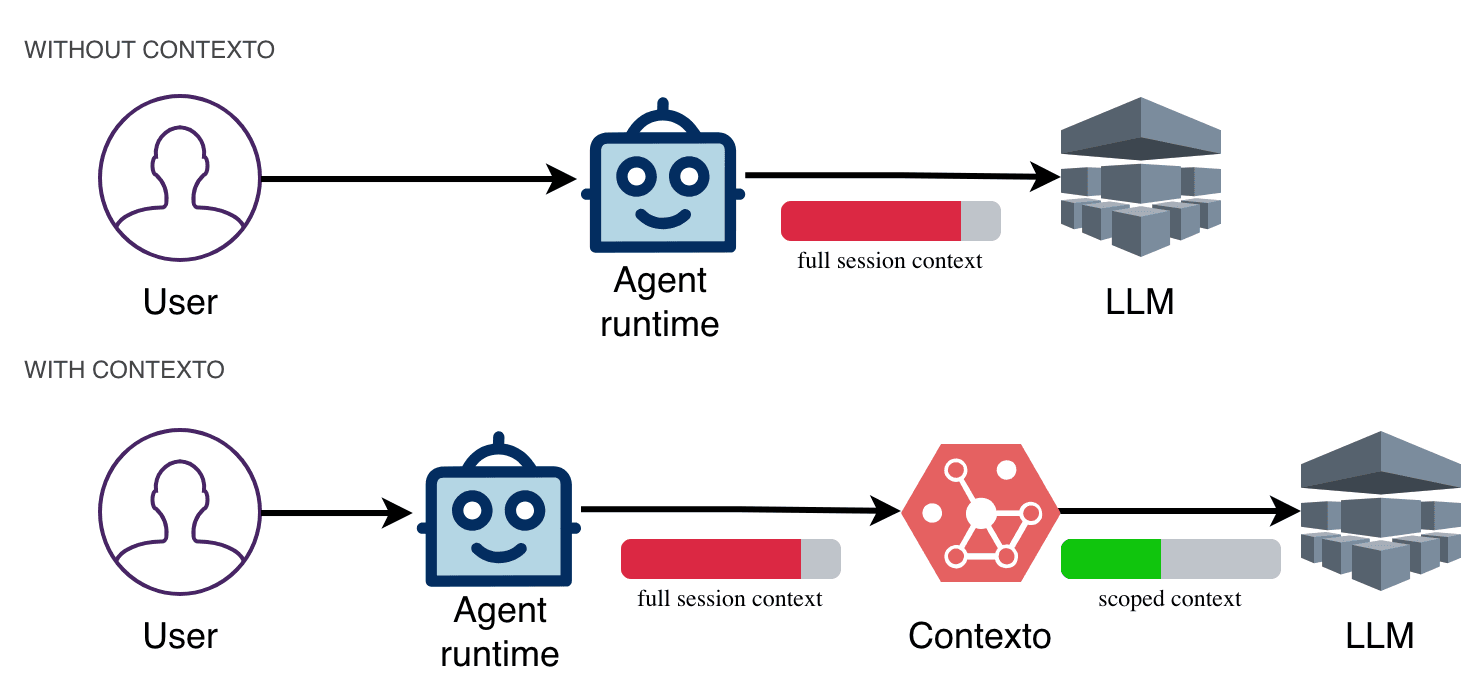
How It Works
During an agent session, Contexto has two core responsibilities: storing prior work in a structured way, and retrieving the right context for the current step.
Storage: Episodes and Mindmap
The first question is what to store. Most systems store individual messages. Contexto stores episodes as the first-class unit of context. An episode is one complete agent turn: the user message, tool calls, tool results, and the agent’s response. Because tool results and intermediate decisions are often what the agent needs later, we ensure evidence and decisions stay together as a single retrievable unit.
Contexto keeps the active context window small by maintaining a sliding window of recent episodes and compacting older ones early. This leaves enough room for long-running agents to keep working through additional tool calls and outputs without running into context limits. Older episodes move into Mindmap, Contexto’s indexed long-range store, where related work is grouped using hierarchical clustering. Nothing is flattened into a lossy summary, and raw episodes remain recoverable down to the message level.
Retrieval: Automatic Injection and On-Demand Search
The next question is what to have in context. Most systems either replay the full history or rely on the agent to ask. Contexto retrieves automatically. At each step, Contexto scores stored episodes by their relevance to the current task and by their recency. The highest-scoring episodes are brought back into the context window, so the agent gets the prior work it needs without dragging in the full session history.
If automatic retrieval is not enough, the agent can explicitly search older episodes and traces using retrieval tools. This is the recovery path. Old work is not lost. It stays accessible when the agent needs to reopen it.
Putting It Together
Eight turns in, the agent has scaffolded the project, set up the database, configured auth, and is now preparing to deploy. Recent work like Run CI checks and Review deploy checklist stays in the sliding window. Older episodes have already been compacted into Mindmap and grouped by topic.
Now the user asks to deploy to staging. The sliding window has the pre-deployment checks, but the deploy target and environment variables were configured back in the original scaffold step. Contexto scores stored episodes against the current task and pulls the Project scaffold episode back into the context window. The agent gets the deployment configuration it needs without carrying the schema, data import, and auth work that do not matter for this step.
What This Gets You
Constraints survive compaction and get retrieved when relevant, even many turns later. Tool outputs stop bloating the active window. The agent stops repeating work it has already done. Old work stays recoverable instead of being compressed away.
Instead of collapsing as the session grows, context compounds. The agent keeps the working set it needs now, while earlier work stays structured, retrievable, and available when it becomes relevant again. The active context stays small enough for the agent to keep making tool calls and moving forward without running into context limits.
What is next?
Contexto today manages context for a single long-running agent. The next step is scoped sub-agents.
When a task branches (reviewing multiple files, comparing documents, investigating several hypotheses), the main agent should not carry all of that intermediate work in its own context. Instead, it spins up sub-agents the way functions call functions: each with only the context that subtask needs, each returning a structured result. The main agent gets the output without carrying the full trace. This is horizontal scaling of agent attention, not just compute. Context stays structured and lossless at every level.