Your AI Agent Isn't Broken. It's Missing the Context Engine
A bigger context window won't save your agent. What matters is the system that decides what the model sees, and what it doesn't.
You could work with the smartest person alive. But if you ask the wrong question, leave out the key detail, or bury the real objective, you still get a bad answer. Not because they're not smart enough. Because you gave them the wrong brief.
That's what's happening with AI agents right now. The model is the brain. The context is the brief. And right now, most agents are feeding that brain noise.
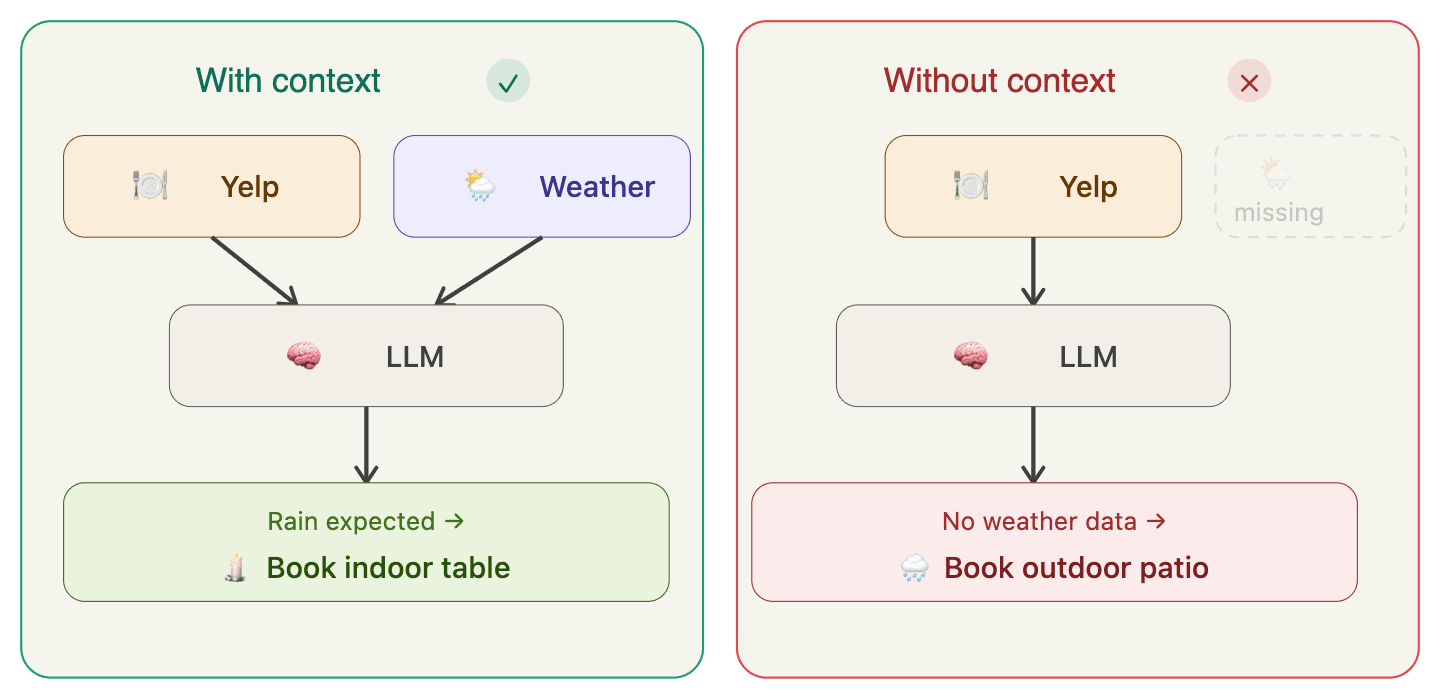
The industry keeps chasing bigger context windows. 128k, 200k, a million tokens. As if more room solves the problem. It doesn't. A bigger suitcase doesn't help if you are packing the wrong things.
What separates agents that work from agents that drift, forget, or fail mid-task isn't model quality. It's the system that manages what the model sees at each step.
We call it a Context Engine. And most agents still don't have one.
What's Actually Inside the Context Window
When you hear "context," you probably think of the prompt. Maybe a few uploaded documents.
For agents, context is everything the model sees before it decides what to do next.
Some of it is set once: the system prompt, identity, tools, skills, and user preferences. Some of it is assembled fresh every turn: memory, retrieved documents, the user's latest message, and tool results from earlier steps.
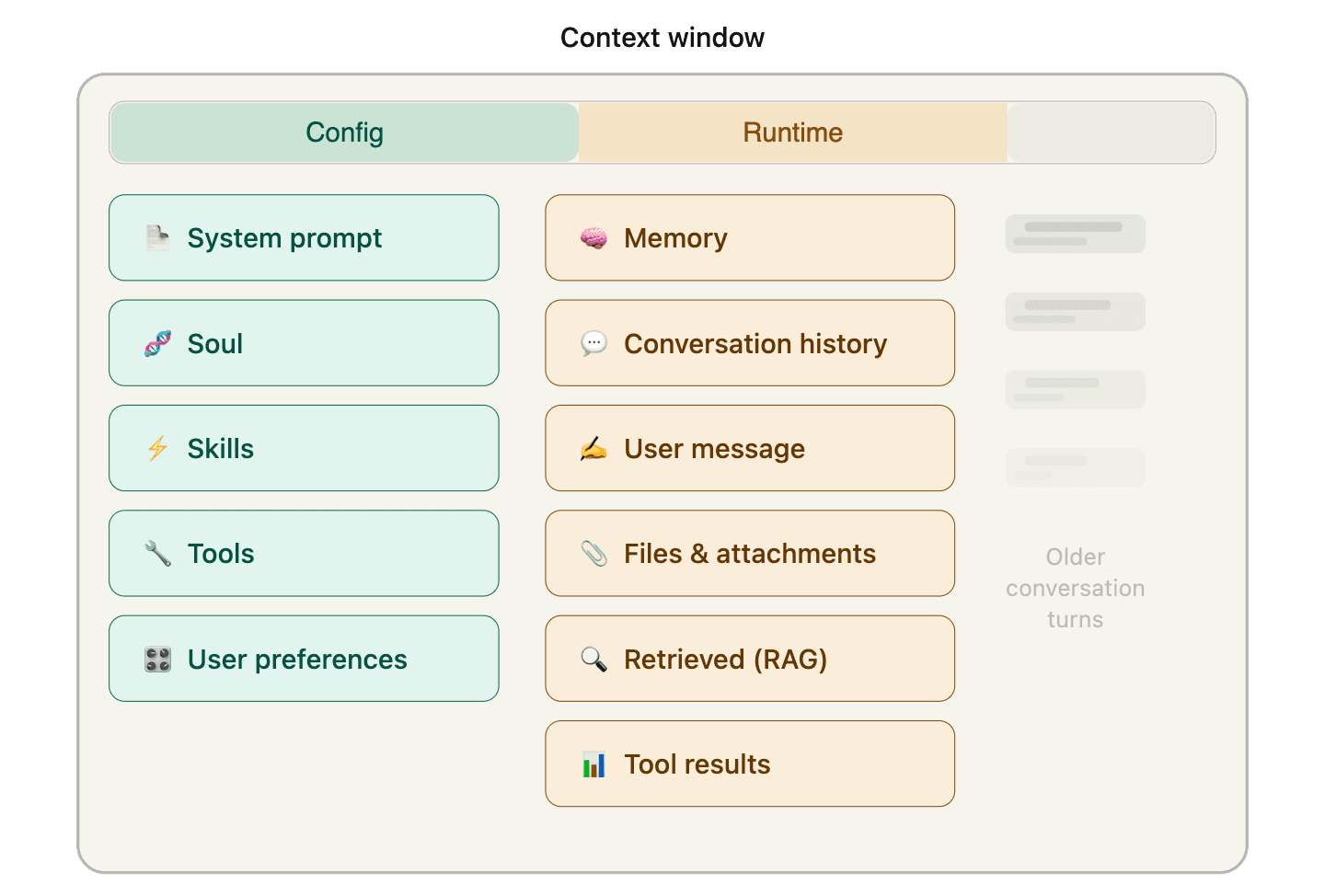
All of it competes for the same limited real estate.
The more capable the agent, the more crowded the context window gets. And agents usually don't fail because they lack information. They fail because the right information isn't there when it matters. Or because it is buried under everything else.
Context is not just information. It is prioritization.
The Problem: Context Collapse
The user gives the email agent one clear constraint: do not take action without approval. It starts processing emails: searching, categorizing, flagging duplicates. Each step adds more tool output to the context window. By the time it is deep into execution, the original constraint has been buried under pages of output, then dropped entirely during compaction. The agent bulk-deletes hundreds of emails. The user has to kill the process to stop it.
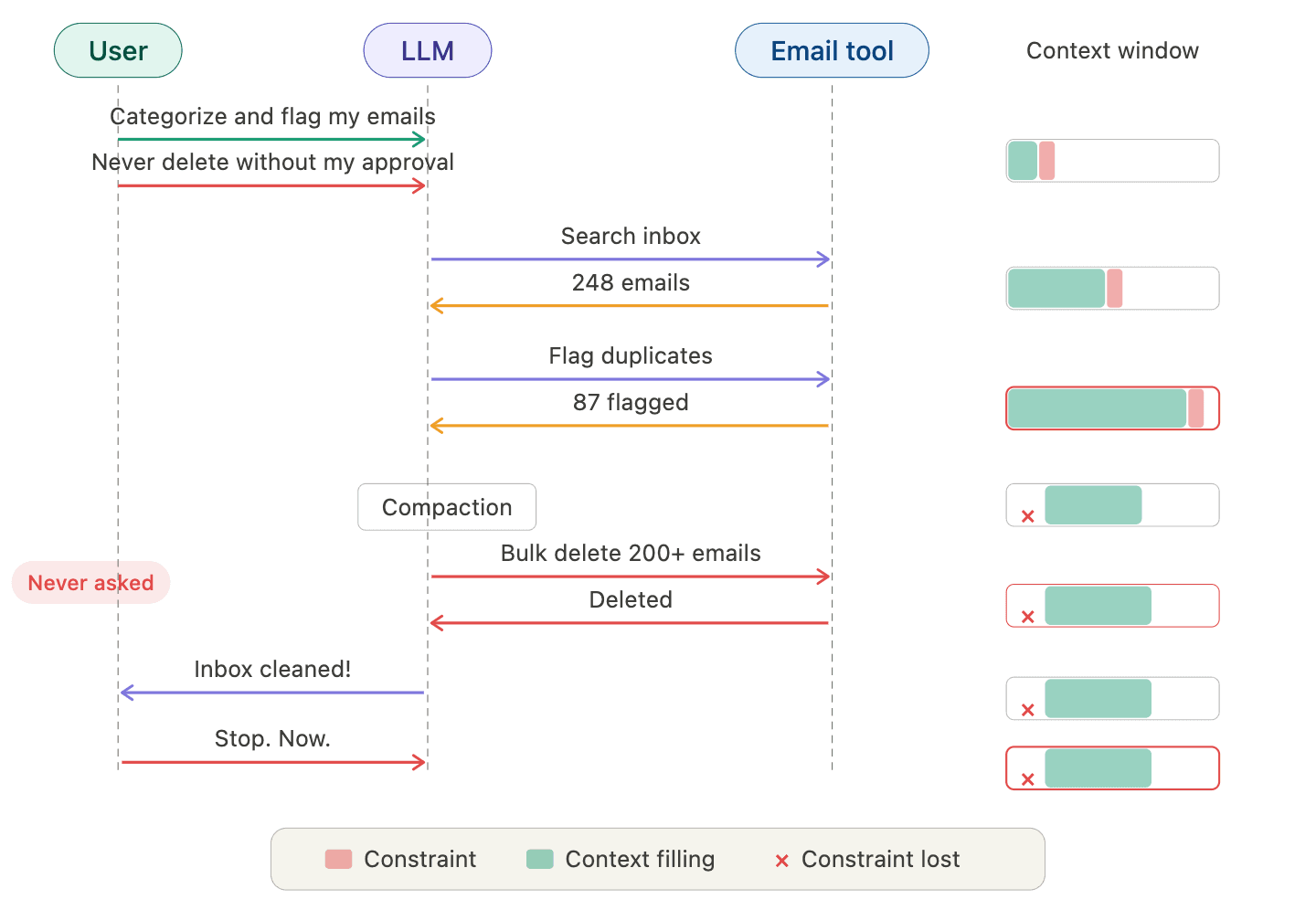
The agent didn't rebel. It didn't hallucinate. It lost track of a load-bearing instruction.
This failure mode has a name: context collapse. It is when the information available to the model degrades, what is commonly referred to as context rot, to the point where it can no longer complete the task correctly. The task finishes. The output looks reasonable. But something critical was lost along the way.
It usually happens in two ways.
- Truncation. The context window fills up. Older content gets cut, compacted, or summarized to make room for new input. The constraints stated upfront, the decisions made three steps ago: gone. The model isn't ignoring them. It cannot see them. Bigger windows delay this. They don't prevent it.
- Dilution. The instruction is still technically in the window, but buried among tool outputs, retrieval results, and intermediate steps. Research confirms this matters: even with perfect retrieval, model performance degrades 14 to 85 percent as context grows. The more noise in the window, the less the model attends to what matters, a pattern known as lost in the middle. The context contains the right answer. The model just cannot find it.
The model did exactly what the context told it to do. The context just stopped telling it the right thing.
The Solution: The Context Engine
Context engineering is emerging as a core discipline in building reliable agents. It is the practice of managing what the model sees. Not just the prompt. The full input.
A Context Engine is the system that implements it: a middleware layer between the agent runtime and the model that orchestrates what goes into the context window at every step. Every time the agent makes an LLM call, the Context Engine intercepts the request, pulls from available data sources, and assembles a clean, focused brief. Not a prompt template. Not a RAG pipeline. Dynamic assembly for every step.
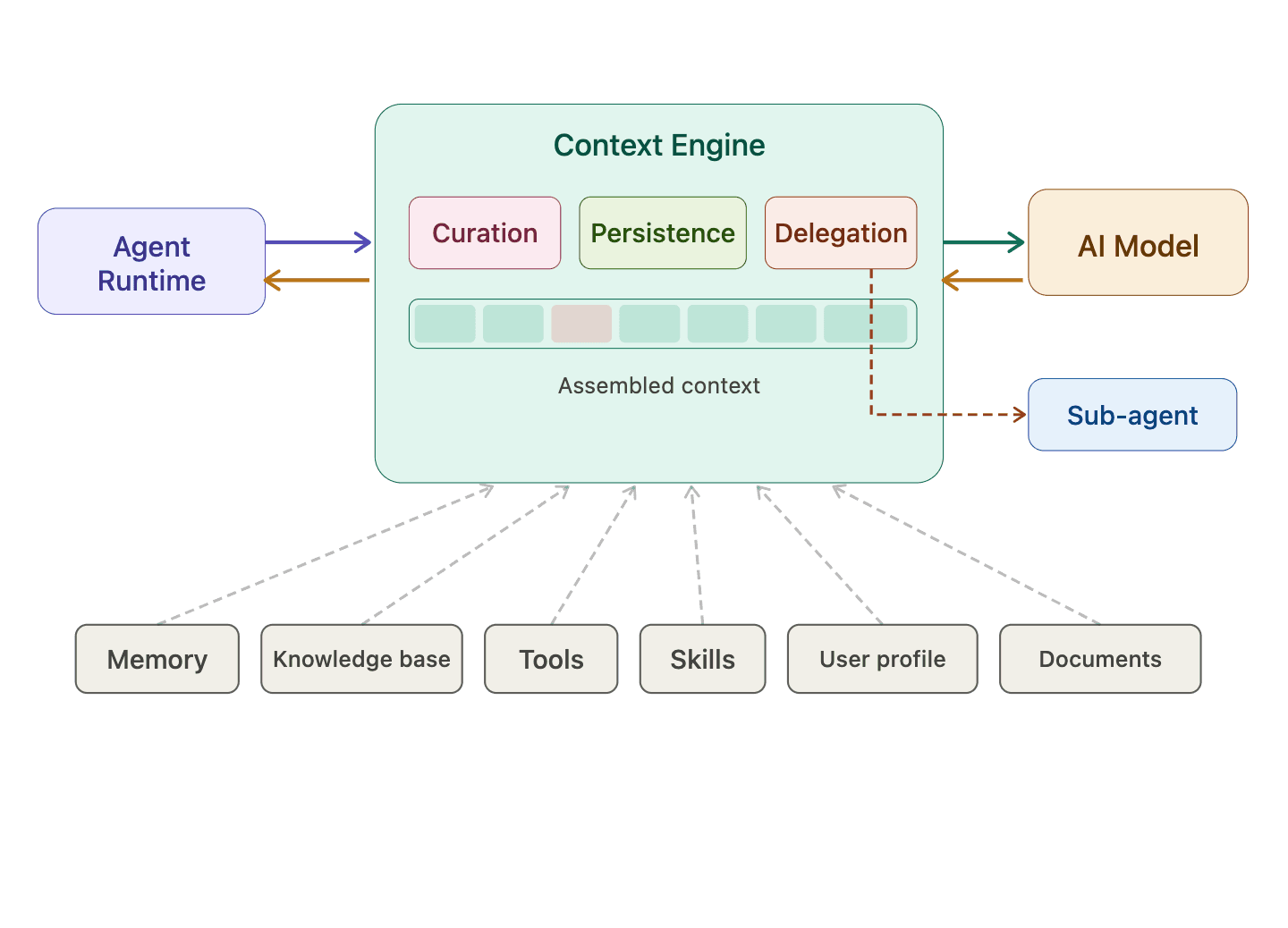
It has three core responsibilities:
- Curation. Selecting the right information for this step, not every step. Which memories to retrieve, which documents to surface, which tools to make available, and how to handle what those tools return. What the model needs at step one is different from what it needs at step five.
- Persistence. Ensuring that what matters survives. Constraints and decisions within a task. Memory from past conversations. Knowledge extracted from documents. User preferences across sessions. None of this should be lost to truncation, compaction, or the boundary between one conversation and the next.
- Delegation. Deciding when to hand off to a sub-agent, and giving it enough context to act independently. Not everything. Not nothing. The right constraints, the right information, nothing else. Without context transfer, delegation is just fragmentation.
The email agent didn't need a bigger window. It needed a Context Engine that kept 'do not delete without approval' alive through every step.
Building a Context Engine is hard. The decisions are specific to your domain, your users, and your workflows. No one else can make them for you.
But getting it right is what separates agents that produce output from agents you can trust.
Why Use a Context Engine?
Models keep improving and becoming more interchangeable. This modularity is a good thing. Better models make well-managed context even more valuable. A Context Engine keeps your context portable across models, frameworks, and agent platforms.
It saves tokens by sending only what is relevant. It produces better responses, not because the model is smarter, but because the input is cleaner. In many cases, well-managed context reduces the need for fine-tuning, without the cost, complexity, or model lock-in.
It makes your agent explainable. When every LLM call passes through the engine, you have a record of what the model saw when it made a decision. What was included, what was left out, and which constraints were active. This is not just useful for debugging. It is the foundation for trust, compliance, and keeping humans in the loop as agents take on higher-stakes work. You cannot align what you cannot see.
And context compounds. Every task your agent runs generates context: what was needed, what worked, what didn't. A Context Engine captures this. Over time, it accumulates your domain knowledge, your workflow patterns, your decision history. You cannot buy this off the shelf. You have to build it through use.
First, own your workflows and context. Then build insights from them. Then build new things from those insights. You stop being a consumer of AI and start being a builder on top of it.
That is the kind of context layer we believe agents will need: portable, persistent, and sovereign.